Archive for 2021
Hedge 101: In Situ OAM
Understanding the flow of a packet is difficult in modern networks, particularly data center fabrics with their wide fanout and high ECMP counts. At the same time, solving this problem is becoming increasingly important as quality of experience becomes the dominant measure of the network. A number of vendor-specific solutions are being developed to solve this problem. In this episode of the Hedge, Frank Brockners and Shwetha Bhandari join Alvaro Retana and Russ White to discuss the in-situ OAM work currently in progress in the IPPM WG of the IETF.
Thoughts on the Collapsed Spine
One of the designs I’ve been encountering a lot of recently is a “collapsed spine” data center network, as shown in the illustration below.
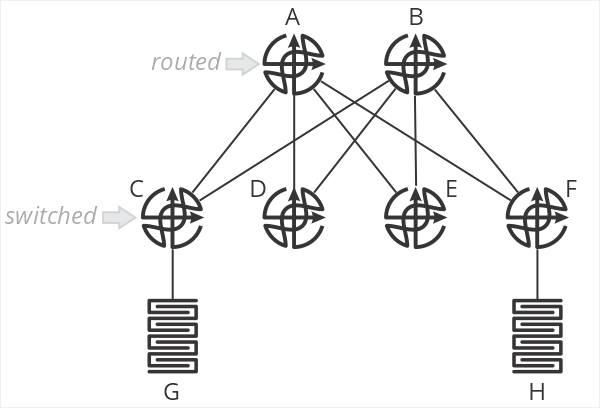
In this design, and B are spine routers, while C-F are top of rack switches. The terminology is important here, because C-F are just switches—they don’t route packets. When G sends a packet to H, the packet is switched by C to A, which then routes the packet towards F, which then switches the packet towards H. C and F do not perform an IP lookup, just a MAC address lookup. A and B are responsible for setting the correct next hop MAC address to forward packets through F to H.
What are the positive aspects of this design? Primarily that all processing is handled on the two spine routers—the top of rack switches don’t need to keep any sort of routing table, nor do any IP lookups. This means you can use very inexpensive devices for your ToR. In brownfield deployments, so long as the existing ToR devices can switch based on MAC addresses, existing hardware can be used.
This design also centralizes almost all aspects of network configuration and management on the spine routers. There is little (if anything) configured on the ToR devices.
What about negative aspects? After all, if you haven’t found the tradeoffs, you haven’t looked hard enough. What are they here?
First, I’m struggling to call this a “fabric” at all—it’s more of a mash-up between a traditional two-layer hierarchical design with a routed core and switched access. Two of the points behind a fabric are the fabric doesn’t have any intelligence (all ports are undifferentiated Ethernet) and all the devices in the fabric are the same.
I suppose you could say the topology itself makes it more “fabric-like” than “network-like,” but we’re squinting a bit either way.
The second downside of this design is that it impacts the scaling properties of the fabric. This design assumes you’ll have larger/more intelligent devices in the spine, and smaller/less intelligent devices in the ToR. One of my consistent goals in designing fabrics has always been to push as close to single-sku as possible—use the same device in every position in the fabric. This greatly simplifies instrumentation, troubleshooting, and supply chain management.
One of the primary points of moving from a network in the more traditional sense to a “true fabric” is to radically simplify the network—this design doesn’t seem like it’s as “simple,” on the network side of things, as it could be. Again, something of a “mash-up” of a simpler fabric and a more traditional two-layer hierarchical routed/switched network.
Scale-out is problematic in this design, as well. You’d need to continue pushing cheap/low-intelligence switches along the edge, and adding larger devices in the spine to make this work over time. At some point, say when you have eight or sixteen spines, you’d be managing just as much configuration—and configuration that’s necessarily more complex because you’re essentially managing remote ports rather than local ones—as you would by just moving routing down to the ToR devices. There’s some scale point here with this design where it’s adding overhead and unnecessary complexity to save a bit of money on ToR switches.
When making the choice between OPEX and CAPEX, we should all know which one to pick.
Where would I use this kind of design? Probably in a smaller network (small enough not to use chassis devices in the spine) which will never need to be scaled out. I might use it as a transition mechanism to a full fabric at some point in the future, but I would want a well-designed planned to transition—and I would want it written in stone that this would not be scaled in the future beyond a specific point.
There’s nothing more permanent in the world than temporary government programs and temporary network designs.
If anyone has other thoughts on this design, please leave them in the comments below.
Hedge 100: Supply Chain Diversity with Brooks Westbrook and Mike Bushong
Most network engineers don’t spend a lot of time thinking about their supply chain—you must call your favorite vendor, order, and a few weeks later the hardware shows up on your loading dock. It’s not so simple any more. If you disaggregate, you need to manage your software and hardware supply chains separately. You need to think about security in your supply chain—is that software package backdoored? Moving to the cloud might seem to solve these problems, but they don’t. Even virtual networks have physical limits.
Listen in as Mike Bushong, Brooks Westbrook, Eyvonne Sharp, Tom Ammon, and Russ White discuss supply chain diversity and security.
Russ’ Rules of Network Design
We have the twelve truths of networking, and possibly Akin’s Laws, but is there a set of rules for network design? I couldn’t find one, so I decided to create one, containing 18 laws I’ve listed below.
Russ’ Rules of Network Design
- If you haven’t found the tradeoffs, you haven’t looked hard enough.
- Design is an iterative process. You probably need one more iteration than you’ve done to get it right.
- A design isn’t finished when everything needed is added, it’s finished when everything possible is taken away.
- Good design isn’t making it work, it’s making it fail gracefully.
- Effective, elegant, efficient. All other orders are incorrect.
- Don’t fix blame; fix problems.
- Local and global optimization are mutually exclusive.
- Reducing state always reduces optimization someplace.
- Reducing state always creates interaction surfaces; shallow and narrow interaction surfaces are better than deep and broad ones.
- The easiest place to improve or screw up a design is at the interaction surfaces.
- The optimum is almost always in the middle someplace; eschew extremes.
- Sometimes its just better to start over.
- There are a handful of right solutions; there is an infinite array of wrong ones.
- You are not immensely smarter than anyone else in networking.
- A bad design with a good presentation is doomed eventually; a good design with a bad presentation is doomed immediately.
- You can only know your part of the system and a little bit about the parts around your part. The rest is rumor and pop psychology.
- To most questions the correct initial answer should be “how many balloons fit in a bag?”
- Virtual environments still have hard physical limits.
Hedge 99

Two things have been top of mind for those who watch the ‘net and global Internet policy—the increasing number of widespread outages, and the logical and physical centralization of the ‘net. How do these things relate to one another? Alban Kwan joins us to discuss the relationship between centralization and widespread outages. You can read Alban’s article on the topic here.
Hedge 098: DRIP with Stuart Card

Drones are becoming—and in many cases have already become—an everyday part of our lives. Drones are used in warfare, delivery services, photography, and recreation. One of the problems facing the world of drones, however, is the strong tie-in between the controller and the drone; this proprietary link limits innovation and reduces the information available to public officials to manage traffic, and even to protect the privacy of drone operators. The DRIP working group is building protocols designed to standardize the drone-to-controller interface, advancing the state of the art in drones and opening up the field for innovation. Stuart Card joins Alvaro Retana and Russ White to discuss DRIP.
Marketing Wins
Off-topic post for today …
In the battle between marketing and security, marketing always wins. This topic came to mind after reading an article on using email aliases to control your email—
One of the most basic things you can do to increase your security against phishing attacks is to have two email addresses, one you give to financial institutions and another one you give to “everyone else.” It would be nice to have a third for newsletters and marketing, but this won’t work in the real world. Why?
Because it’s very rare to find a company that will keep two email addresses on file for you, one for “business” and another for “marketing.” To give specific examples—my mortgage company sends me both marketing messages in the form of a “newsletter” as well as information about mortgage activity. They only keep one email address on file, though, so they both go to a single email address.
A second example—even worse in my opinion—is PayPal. Whenever you buy something using PayPal, the vendor gets the email address associated with the account. That’s fine—they need to send me updates on the progress of the item I ordered, etc. But they also use this email address to send me newsletters … and PayPal sends any information about account activity to the same email address.
Because of the way these things are structured, I cannot separate information about my account from newsletters, phishing attacks, etc. Since modern Phishing campaigns are using AI to create the most realistic emails possible, and most folks can’t spot a Phish anyway, you’d think banks and financial companies would want to give their users the largest selection of tools to fight against scams.
But they don’t. Why?
Because—if your financial information is mingled with a marketing newsletter, you’ll open the email to see what’s inside … you’ll pay attention. Why spend money helping your users not pay attention to your marketing materials by separating them from “the important stuff?”
When it comes to marketing versus security, marketing always wins. Somehow, we in IT need to do better than this.