DESIGN
Thoughts on the Collapsed Spine
One of the designs I’ve been encountering a lot of recently is a “collapsed spine” data center network, as shown in the illustration below.
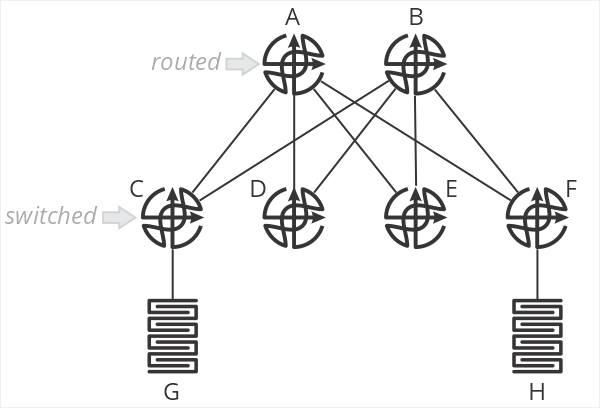
In this design, and B are spine routers, while C-F are top of rack switches. The terminology is important here, because C-F are just switches—they don’t route packets. When G sends a packet to H, the packet is switched by C to A, which then routes the packet towards F, which then switches the packet towards H. C and F do not perform an IP lookup, just a MAC address lookup. A and B are responsible for setting the correct next hop MAC address to forward packets through F to H.
What are the positive aspects of this design? Primarily that all processing is handled on the two spine routers—the top of rack switches don’t need to keep any sort of routing table, nor do any IP lookups. This means you can use very inexpensive devices for your ToR. In brownfield deployments, so long as the existing ToR devices can switch based on MAC addresses, existing hardware can be used.
This design also centralizes almost all aspects of network configuration and management on the spine routers. There is little (if anything) configured on the ToR devices.
What about negative aspects? After all, if you haven’t found the tradeoffs, you haven’t looked hard enough. What are they here?
First, I’m struggling to call this a “fabric” at all—it’s more of a mash-up between a traditional two-layer hierarchical design with a routed core and switched access. Two of the points behind a fabric are the fabric doesn’t have any intelligence (all ports are undifferentiated Ethernet) and all the devices in the fabric are the same.
I suppose you could say the topology itself makes it more “fabric-like” than “network-like,” but we’re squinting a bit either way.
The second downside of this design is that it impacts the scaling properties of the fabric. This design assumes you’ll have larger/more intelligent devices in the spine, and smaller/less intelligent devices in the ToR. One of my consistent goals in designing fabrics has always been to push as close to single-sku as possible—use the same device in every position in the fabric. This greatly simplifies instrumentation, troubleshooting, and supply chain management.
One of the primary points of moving from a network in the more traditional sense to a “true fabric” is to radically simplify the network—this design doesn’t seem like it’s as “simple,” on the network side of things, as it could be. Again, something of a “mash-up” of a simpler fabric and a more traditional two-layer hierarchical routed/switched network.
Scale-out is problematic in this design, as well. You’d need to continue pushing cheap/low-intelligence switches along the edge, and adding larger devices in the spine to make this work over time. At some point, say when you have eight or sixteen spines, you’d be managing just as much configuration—and configuration that’s necessarily more complex because you’re essentially managing remote ports rather than local ones—as you would by just moving routing down to the ToR devices. There’s some scale point here with this design where it’s adding overhead and unnecessary complexity to save a bit of money on ToR switches.
When making the choice between OPEX and CAPEX, we should all know which one to pick.
Where would I use this kind of design? Probably in a smaller network (small enough not to use chassis devices in the spine) which will never need to be scaled out. I might use it as a transition mechanism to a full fabric at some point in the future, but I would want a well-designed planned to transition—and I would want it written in stone that this would not be scaled in the future beyond a specific point.
There’s nothing more permanent in the world than temporary government programs and temporary network designs.
If anyone has other thoughts on this design, please leave them in the comments below.
Russ’ Rules of Network Design
We have the twelve truths of networking, and possibly Akin’s Laws, but is there a set of rules for network design? I couldn’t find one, so I decided to create one, containing 18 laws I’ve listed below.
Russ’ Rules of Network Design
- If you haven’t found the tradeoffs, you haven’t looked hard enough.
- Design is an iterative process. You probably need one more iteration than you’ve done to get it right.
- A design isn’t finished when everything needed is added, it’s finished when everything possible is taken away.
- Good design isn’t making it work, it’s making it fail gracefully.
- Effective, elegant, efficient. All other orders are incorrect.
- Don’t fix blame; fix problems.
- Local and global optimization are mutually exclusive.
- Reducing state always reduces optimization someplace.
- Reducing state always creates interaction surfaces; shallow and narrow interaction surfaces are better than deep and broad ones.
- The easiest place to improve or screw up a design is at the interaction surfaces.
- The optimum is almost always in the middle someplace; eschew extremes.
- Sometimes its just better to start over.
- There are a handful of right solutions; there is an infinite array of wrong ones.
- You are not immensely smarter than anyone else in networking.
- A bad design with a good presentation is doomed eventually; a good design with a bad presentation is doomed immediately.
- You can only know your part of the system and a little bit about the parts around your part. The rest is rumor and pop psychology.
- To most questions the correct initial answer should be “how many balloons fit in a bag?”
- Virtual environments still have hard physical limits.
The Grass is Always Greener

This last week I was talking to someone at a small startup that intends to eliminate all the complex routing from campus networks. In the past, when reading blog posts about Kubernetes, I’ve read about how it was designed to eliminate routing protocols because “routing protocols are so complex.”
Color me skeptical.
There are two reasons for complexity in a design. The first is you’re solving a hard problem. The second is you’ve made bad design choices in the past, and you’re pasting complexity on top to solve some perceived problem (whether perceived or real).
The problem with all this talk about building something that’s “less complex” is people tend to see complexity of the first kind and think, “we can get rid of that complexity if we start over.” Failing to understand the past before building the future is a recipe for repeated failures of the same kind. Building a network without a distributed routing protocol hasn’t been tried before either, right? Well, yes, it has … We either forget how it turned out, or we say “well, that’s not the same thing I’m talking about here” (just like “real socialism hasn’t ever been tried”).
Even worse, they think they get rid of second and third kinds of complexity by starting over, or getting the humans out of the decision-making loop, or focusing on the data. Our modern penchant for relying “the data,” without ever thinking about the source of the data or how the data has been shaped and interpreted, is truly breathtaking.
They look over the horizon, see an unspoiled field, and think “the grass really is greener on the other side.”
Get rid of all those complex dynamic routing protocols … get rid of all those humans making decisions, so the decisions are “data driven” … and everything will be so much better.
Adding complexity to solve hard real-world problems is just the way things are, and they will always be, so the first reason for complexity will always be with us. People make mistakes, don’t see into the future perfectly, or just don’t have a perfect understanding of the system (technical debt), so the second kind of complexity will always be with us. You can’t “fix” people—God save us from those who think they can. The grass isn’t always greener—it just always looks that way.
What’s the practical upshot? Networks are always going to be complex. It’s just the nature of the problem being solved.
We add complexity because we fail to ask the right questions, we don’t understand the system, or we fail to do good design. The solution isn’t to seek out a greener field “out there,” but rather to make the field we currently live in greener by asking the right questions and reducing complexity through good design. Sometimes you might even need to start over with a new network … but when you start thinking about starting over with a newly designed set of protocols because the old ones are “too complex,” you need to ask how those old ones got that way, and how you’re going to stop the new ones from getting to the same place.
The grass is always greener because you looking at it through green-colored lenses just as the new grass is in its full flush, and before the weeds have had a chance to take over.
Learn how old things worked before you fall for some new “modern wonder” that’s going to solve every problem. The complexity in old things will show you where you can expect to find complexity grow up in new things.
NATs, PATs, and Network Hygiene
While reading a research paper on address spoofing from 2019, I ran into this on NAT (really PAT) failures—
The authors state 49% of the NATs they discovered in their investigation of spoofed addresses fail in one of these two ways. From what I remember way back when the first NAT/PAT device (the PIX) was deployed in the real world (I worked in TAC at the time), there was a lot of discussion about what a firewall should do with packets sourced from addresses not indicated anywhere.
If I have an access list including 192.168.1.0/24, and I get a packet sourced from 192.168.2.24, what should the NAT do? Should it forward the packet, assuming it’s from some valid public IP space? Or should it block the packet because there’s no policy covering this source address?
This is similar to the discussion about whether BGP speakers should send routes to an external peer if there is no policy configured. The IETF (though not all vendors) eventually came to the conclusion that BGP speakers should not advertise to external peers without some form of policy configured.
My instinct is the NATs here are doing the right thing—these packets should be forwarded—but network operators should be aware of this failure mode and configure their intentions explicitly. I suspect most operators don’t realize this is the way most NAT implementations work, and hence they aren’t explicitly filtering source addresses that don’t fall within the source translation pool.
In the real world, there should also be a box just outside the NATing device that’s running unicast reverse path forwarding checks. This would resolve these sorts of spoofed packets from being forwarding into the DFZ—but uRPF is rarely implemented by edge providers, and most edge connected operators (enterprises) don’t think about the importance of uRPF to their security.
All this to say—if you’re running a NAT or PAT, make certain you understand how it works. Filters are tricky in the best of circumstances. NAT and PATs just make filters trickier.
The Hedge 85: Terry Slattery and the ROI of Automation
It’s easy to assume automation can solve anything and that it’s cheap to deploy—that there are a lot of upsides to automation, and no downsides. In this episode of the Hedge, Terry Slattery joins Tom Ammon and Russ White to discuss something we don’t often talk about, the Return on Investment (ROI) of automation.
Is it really the best just because its the most common?
I cannot count the number of times I’ve heard someone ask these two questions—
- What are other people doing?
- What is the best common practice?
While these questions have always bothered me, I could never really put my finger on why. I ran across a journal article recently that helped me understand a bit better. The root of the problem is this—what does best common mean, and how can following the best common produce a set of actions you can be confident will solve your problem?
Bellman and Oorschot say best common practice can mean this is widely implemented. The thinking seems to run something like this: the crowd’s collective wisdom will probably be better than my thinking… more sets of eyes will make for wiser or better decisions. Anyone who has studied the madness of crowds will immediately recognize the folly of this kind of state. Just because a lot of people agree it’s a good idea to jump off a cliff does not mean it is, in fact, a good idea to jump off a cliff.
Perhaps it means something closer to this is no worse than our competitors. If that’s the meaning, though, it’s a pretty cynical result. It’s saying, “I don’t mind condemning myself to mediocrity so long as I see everyone else doing the same thing.” It doesn’t sound like much of a way to grow a business.
The authors do provide their definition—
The thinking seems to run something like this—it’s likely that everyone else has tried many different ways of doing this; that they have all settled on doing this, this way, means all those other methods are probably not as good as this one for some reason.
Does this work? There’s no way to tell without further investigation. How many of the other folks doing “this” spent serious time trying alternatives, and how many just decided the cheapest way was the best no matter how poor the result might be? In fact, how can we know what the results of doing things “this way” have in all those other networks? Where would we find this kind of information?
In the end, I can’t ever make much sense out of the question, “what is everyone else doing?” Discovering what everyone else is doing might help me eliminate possibilities (that didn’t work for them, so I certainly don’t want to try it), or it might help me understand the positive and negative attributes of a given solution. Still, I don’t understand why “common” should infer “best.”
The best solution for this situation is simply going to be the best solution. Feel free to draw on many sources, but don’t let other people determine what you should be doing.
The Effectiveness of AS Path Prepending (2)
Last week I began discussing why AS Path Prepend doesn’t always affect traffic the way we think it will. Two other observations from the research paper I’m working off of are:
- Adding two prepends will move more traffic than adding a single prepend
- It’s not possible to move traffic incrementally by prepending; when it works, prepending will end up moving most of the traffic from one inbound path to another
A slightly more complex network will help explain these two observations.

Assume AS65000 would like to control the inbound path for 100::/64. I’ve added a link between AS65001 and 65002 here, but we will still find prepending a single AS to the path won’t make much difference in the path used to reach 100::/64. Why?
Because most providers will have a local policy configured—using local preference—that causes them to choose any available customer connection over other paths. AS65001, on receiving the route to 100::/64 from AS65000, will set the local preference so it will prefer this route over any other route, including the one learned from AS65002. So while the cause is a little different in this case than the situation covered in the first post, the result is the same.
We can, of course, prepend twice onto the AS Path rather than once. What impact would that have here? It still won’t impact the traffic originating in 65005 because AS65001 is the only path available towards 100::64 from their perspective. Prepending cannot change anything if there’s only one path.
However, if most of the traffic destined to 100::/64 coming from AS65006, 7, and 8 rather than from AS65005, prepending two times will allow AS65000 to shift the traffic from the path through AS65002 to the path through AS65001. This example might seem a little contrived. Still, it’s pretty similar to networks that have one connection to some local provider (a cable company or something similar) and one connection to a more prominent national or international provider. Any time you are connected to two different providers who have different ranges of connectivity, prepending two autonomous systems on the AS Path will probably be able to shift traffic from one inbound link to another.
What about prepending more than two hops to the AS Path? Each additional prepend going to shift smaller amounts of traffic. It makes sense that increasing the number of prepends doesn’t shift much more because the further away you get from the edge of the Internet, the more fully connected the autonomous systems are, and the more likely you are to run into some other policy that will override the AS Path in determining the best path. The average length of the AS Path in the Internet is around four; prepending more than this normally won’t have much of an effect on traffic flow
The second question above can also be answered by looking at this network. Why can’t you shift traffic incrementally by prepending onto the AS Path? Because the connectivity close to the edge is probably not meshy enough. You can’t shift over just the traffic from one AS or another; you can only shift traffic from the entire set of autonomous systems behind your upstream from one inbound link to another. You can adjust traffic on a per-prefix basis, however, which can be useful for balancing between two inbound links.
What can you do to control inbound traffic with more certainty? Take a look at this older post for thoughts on using communities and de-aggregation to steer traffic.