CONTENT TYPE
Hedge 104: Automation with David Gee
Automation is often put forward as the answer to all our problems—but without a map, how can we be certain we are moving in the right direction? David Gee joins Tom Ammon and Russ White on this episode of the Hedge to talk about automata without a map. Where did we come from, what are we doing with automation right now, and what do we need to do to map out a truly better future?
Hedge 103: BGP Security with Geoff Huston
Our community has been talking about BGP security for over 20 years. While MANRS and the RPKI have made some headway in securing BGP, the process of deciding on a method to provide at least the information providers need to make more rational decisions about the validity of individual routes is still ongoing. Geoff Huston joins Alvaro, Russ, and Tom to discuss how we got here and whether we will learn from our mistakes.
Hedge 102: BGP Security with Geoff Huston
Our community has been talking about BGP security for over 20 years. While MANRS and the RPKI have made some headway in securing BGP, the process of deciding on a method to provide at least the information providers need to make more rational decisions about the validity of individual routes is still ongoing. Geoff Huston joins Alvaro, Russ, and Tom to discuss how we got here and whether we will learn from our mistakes.
Keith’s Law (1)
I sometimes reference Keith’s Law in my teaching, but I don’t think I’ve ever explained it. Keith’s Law runs something like this:
Any large external step in a system’s capability is the result of many incremental changes within the system.
The reason incremental changes within a system appear as a single large step to outside observers is the smaller changes are normally hidden by abstraction. This is, in fact, the purpose of abstraction—to hide small changes inside a system from external view. Keith’s law is closely related to Clarke’s third law that “Any sufficiently advanced technology is indistinguishable from magic.” What looks like magic from the outside is really just a bunch of smaller things—each easier to understand on its own—combined into one single “thing” through abstraction.
If you’ve read this far, you’re probably thinking—what does this have to do with network engineering?
Well, several things, really.
First—the network is just an abstraction that moves packets to its users. Moving packets seems so … simple … to network users. You put data in here, and data comes out over there. All the little stuff that goes into making a network work are lost in the abstraction of the virtual connection between two hosts.
If you want users to understand why building a network is hard, you’re going to have to work hard at it. And you’re not likely to succeed—it’s often better just to live with the reality that users aren’t going to understand. Of course, this isn’t necessarily a bad thing, at least until it’s time to buy hardware and software to make all this magic work.
Second—no-one outside the network is ever going to understand the refactoring, simplification, and new features you’re trying to build into the network on their own. Users will only understand these things when they are related to some bigger picture, something they can see beyond the abstraction the network presents.
If you’re going to justify doing new things, you need to do so in terms of “larger things,” things that can be seen from outside the abstraction.
Third—no-one is going to pat you on the back for all the little things that need to be done to deploy a new major service. From the outside, that new service, or new cost savings, or whatever—it’s all just indistinguishable from magic.
Keith’s law is both good and bad. But it also means you need to learn how to frame your work in a way that users, who don’t have access to the inner workings of the network, can understand why you’re doing what you’re doing.
Turning this around, this also means you shouldn’t accept the “magic” of vendor products. That brilliant new capability your vendor is showing you is really made up of a lot of smaller components. The abstraction is just that—an abstraction. If you really want to understand the positive and negative consequences of deploying something new, you need to look beyond the abstraction.
Hedge 101: In Situ OAM
Understanding the flow of a packet is difficult in modern networks, particularly data center fabrics with their wide fanout and high ECMP counts. At the same time, solving this problem is becoming increasingly important as quality of experience becomes the dominant measure of the network. A number of vendor-specific solutions are being developed to solve this problem. In this episode of the Hedge, Frank Brockners and Shwetha Bhandari join Alvaro Retana and Russ White to discuss the in-situ OAM work currently in progress in the IPPM WG of the IETF.
Thoughts on the Collapsed Spine
One of the designs I’ve been encountering a lot of recently is a “collapsed spine” data center network, as shown in the illustration below.
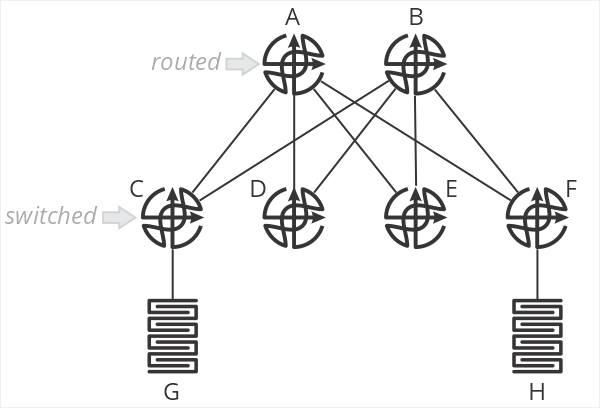
In this design, and B are spine routers, while C-F are top of rack switches. The terminology is important here, because C-F are just switches—they don’t route packets. When G sends a packet to H, the packet is switched by C to A, which then routes the packet towards F, which then switches the packet towards H. C and F do not perform an IP lookup, just a MAC address lookup. A and B are responsible for setting the correct next hop MAC address to forward packets through F to H.
What are the positive aspects of this design? Primarily that all processing is handled on the two spine routers—the top of rack switches don’t need to keep any sort of routing table, nor do any IP lookups. This means you can use very inexpensive devices for your ToR. In brownfield deployments, so long as the existing ToR devices can switch based on MAC addresses, existing hardware can be used.
This design also centralizes almost all aspects of network configuration and management on the spine routers. There is little (if anything) configured on the ToR devices.
What about negative aspects? After all, if you haven’t found the tradeoffs, you haven’t looked hard enough. What are they here?
First, I’m struggling to call this a “fabric” at all—it’s more of a mash-up between a traditional two-layer hierarchical design with a routed core and switched access. Two of the points behind a fabric are the fabric doesn’t have any intelligence (all ports are undifferentiated Ethernet) and all the devices in the fabric are the same.
I suppose you could say the topology itself makes it more “fabric-like” than “network-like,” but we’re squinting a bit either way.
The second downside of this design is that it impacts the scaling properties of the fabric. This design assumes you’ll have larger/more intelligent devices in the spine, and smaller/less intelligent devices in the ToR. One of my consistent goals in designing fabrics has always been to push as close to single-sku as possible—use the same device in every position in the fabric. This greatly simplifies instrumentation, troubleshooting, and supply chain management.
One of the primary points of moving from a network in the more traditional sense to a “true fabric” is to radically simplify the network—this design doesn’t seem like it’s as “simple,” on the network side of things, as it could be. Again, something of a “mash-up” of a simpler fabric and a more traditional two-layer hierarchical routed/switched network.
Scale-out is problematic in this design, as well. You’d need to continue pushing cheap/low-intelligence switches along the edge, and adding larger devices in the spine to make this work over time. At some point, say when you have eight or sixteen spines, you’d be managing just as much configuration—and configuration that’s necessarily more complex because you’re essentially managing remote ports rather than local ones—as you would by just moving routing down to the ToR devices. There’s some scale point here with this design where it’s adding overhead and unnecessary complexity to save a bit of money on ToR switches.
When making the choice between OPEX and CAPEX, we should all know which one to pick.
Where would I use this kind of design? Probably in a smaller network (small enough not to use chassis devices in the spine) which will never need to be scaled out. I might use it as a transition mechanism to a full fabric at some point in the future, but I would want a well-designed planned to transition—and I would want it written in stone that this would not be scaled in the future beyond a specific point.
There’s nothing more permanent in the world than temporary government programs and temporary network designs.
If anyone has other thoughts on this design, please leave them in the comments below.
Hedge 100: Supply Chain Diversity with Brooks Westbrook and Mike Bushong
Most network engineers don’t spend a lot of time thinking about their supply chain—you must call your favorite vendor, order, and a few weeks later the hardware shows up on your loading dock. It’s not so simple any more. If you disaggregate, you need to manage your software and hardware supply chains separately. You need to think about security in your supply chain—is that software package backdoored? Moving to the cloud might seem to solve these problems, but they don’t. Even virtual networks have physical limits.
Listen in as Mike Bushong, Brooks Westbrook, Eyvonne Sharp, Tom Ammon, and Russ White discuss supply chain diversity and security.