WRITTEN
It’s not a CLOS, it’s a Clos
Way back in the day, when telephone lines were first being installed, running the physical infrastructure was quite expensive. The first attempt to maximize the infrastructure was the party line. In modern terms, the party line is just an Ethernet segment for the telephone. Anyone can pick up and talk to anyone else who happens to be listening. In order to schedule things, a user could contact an operator, who could then “ring” the appropriate phone to signal another user to “pick up.” CSMA/CA, in essence, with a human scheduler.
This proved to be somewhat unacceptable to everyone other than various intelligence agencies, so the operator’s position was “upgraded.” A line was run to each structure (house or business) and terminated at a switchboard. Each line terminated into a jack, and patch cables were supplied to the operator, who could then connect two telephone lines by inserting a jumper cable between the appropriate jacks.
An important concept: this kind of operator driven system is nonblocking. If Joe calls Susan, then Joe and Susan cannot also talk to someone other than one another for the duration of their call. If Joe’s line is tied up, when someone tries to call him, they will receive a busy signal. The network is not blocking in this case, the edge is—because the node the caller is trying to reach is already using 100% of its available bandwidth for an existing call. This is called admission control; all non-blocking networks must either be provisioned so the sum total of the transmitters cannot consume the whole of the cross-sectional bandwidth available in the network, or they must have effective admission control.
Blocking networks did exist in the form of trunk connections, or connections between these switch panels. Trunk connections not only consumed ports on the switchboard, they were expensive to build, and required a lot of power to run. Hence, making a “long distance call” costs money because it consumed a blocking resource. It is only when we get to packet switched digital networks that the cost of a “long distance call” drops to the rough equivalent of a “normal” call, and we see “long distance” charges fade into memory (many of my younger readers have never been charged for “long distance calls,” in fact, and may not even know what I’m talking about).
The human operators were eventually replaced by relays.

The old “crank to ring” phones were replaced with “dial phones,” which break the circuit between the phone and the relay to signal a digit being dialed. The process begins when you lift the handset, which causes voltage to run across the line. Spinning the dial breaks the circuit once for each digit on the dial. Each time the circuit breaks, the armature on this stack of circular relays is moved. The first digit dialed causes the relay to move up (or down, depending on the relay) the stack. When you pause for a second before dialing the second number, the motors reset so the arm will now move around the circle, starting with the zero position. When it reaches this spot, the arm connects your physical line to another relay, which then repeats the process, ultimately reaching the line of the person you want to call and creating a direct electrical connection between the caller and the receiver. We used to have huge banks of these relays, accompanied by 66 style punch-down blocks, and sometimes (in newer systems) spin-down connections for permanent circuits. We mostly “troubleshot” them with WD-40 and electrical contact solution from spray cans (yes, I have personal experience).
These huge relay banks became unwieldy to support, of course, so they were eventually replaced with fabrics—crossbar fabrics.

In a crossbar fabric, each device is “attached twice,” once on the send side, and once on the receive side. When you place a call, your “send” is connected to the receivers “receive” by making an electrical connection where your “send” line intersects with the receivers “receive” line. All of this hardware, however, has the property of scaling up rather than out. In order to create a larger telephone switch, you simply have to buy a larger fabric of some kind. You cannot “add to” a fabric once it is built, which means when a region outgrows its fabric, you either must install a new on and connect the two fabrics with trunk lines, you must rip the entire fabric out and replace it.
This is the problem Edson Erwin, and later Charles Clos, were trying to solve—how do you build a large-scale switching fabric out of simple components, and yet scale to virtually any size. While Erwin invented the concept in 1938, the concept was formalized by Clos in 1952. Charles Clos, by the way, was French, so the proper pronunciation is “klo,” with a long “o.”
The solution was to use four port switches (or relays, in the case of circuits), each of which are connected into a familiar looking fabric.

This was designed to be a unidirectional fabric, with each edge node (leaf) having a send and receive side, much like a crossbar. It is fairly obvious that the fabric is nonblocking on admission control; if a1 connects to b3, then a1’s entire bandwidth is consumed in that connection, so a1 cannot accept any other connections. If d1 also tries to connect to b3, it will receive the traditional “busy signal.” The network does not block, it just refuses to accept the new connection at the edge.
What if you wanted to make this fabric bidirectional? To allow traffic to flow from a1 to b3 while also allowing traffic to flow from a3 to, say, d1? You would “fold” the fabric. This does not involve changing the physical layout at all; folded Clos fabrics are not drawn any differently than non-folded Clos fabrics. They look identical on paper (stop drawing them as if putting a1 and a3 on the same side of the fabric makes them into a “two-stage folded fabric”—this is not what “folded” means). The primary change here is in the “control plane,” or the scheduler, which must be modified to allow traffic to flow in either direction. Packet switching is almost always bidirectional, so all Clos fabrics used in packet switched networks are “folded” in this way.
Another interesting point—you cannot really perform “acceptance flow control” on a packet-switched network, so there is no way to make the fabric “nonblocking.” In a circuit-based network, the number of edge ports can be tied to the amount of cross-sectional bandwidth available in the fabric. You can over-subscribe the fabric by provisioning more ports on the edge than the cross-sectional bandwidth of the fabric itself can support, of course, which makes the fabric non-contending, rather than non-blocking. In a packet-switched network, it just is not possible to perform reliable admission control; because of this, packet switched Clos fabrics, then, are always non-contending rather than non-blocking.
So the next time you put CLOS in a document, or on a white board, don’t. It’s a Clos fabric, not a CLOS fabric. It’s not non-blocking, and you do not “fold” it by drawing it with two stages. Clos fabrics always have an odd number of stages. There is a mathematical reason for this, but this post is already long enough.
Another problem with our common usage of these terms is we call every kind of spine-and-leaf (or leaf-and-spine) fabric a Clos, and we have started calling all kinds of networks, including overlay networks, “fabrics.” This post is already long (as above), so I will leave these for the future.
If you liked this short article, and would like to understand more about fabrics and fabric design, please join me for me upcoming Data Center Design live webinar on Safari Books. I will cover this history there, but I will also cover a lot of other things involved in designing data center fabrics.
Reaction: Overly Attached
The longer you work on one system or application, the deeper the attachment. For years you have been investing in it—adding new features, updating functionality, fixing bugs and corner cases, polishing, and refactoring. If the product serves a need, you likely reap satisfaction for a job well done (and maybe you even received some raises or promotions as a result of your great work).
Attachment is a two-edged sword—without some form of attachment, it seems there is no way to have pride in your work. On the other hand, attachment leads to poorly designed solutions. For instance, we all know the hyper-certified person who knows every in and out of a particular vendor’s solution, and hence solves every problem in terms of that vendor’s products. Or the person who knows a particular network automation system and, as a result, solves every problem through automation.
The most pernicious forms of attachment in the network engineering world are to a single technology or vendor. One of the cycles I have seen play out many times across the last 30 years is: a new idea is invented; this new idea is applied to every possible problem anyone has ever faced in designing or operating a network; the resulting solution becomes overburdened and complicated; people complain about the complexity of the solution and rush to… the next new idea. I could name tens or hundreds of technologies that have been through this cycle over time.
Another related cycle: a team adopts a new technology in order to solve a problem.
Kate points out some very helpful ways to solve over-attachment at an organizational level. For instance, aligning on goals and purpose, and asking everyone to be open to ideas and alternatives. But these organizational level solutions are more difficult to apply at an individual level. How can this be applied to the individual—to your life?
Perhaps the most important piece of advice Kate gives here is ask for stories, not solutions. In telling stories you are not eliminating attachment but refocusing it. Rather than becoming attached to a solution or technology, you are becoming attached to a goal or a narrative. This accepts that you will always be attached to something—in fact, that it is ultimately healthy to be attached to something outside yourself in a fundamental way. The life that is attached to nothing is ugly and self-centered, ultimately failing to accomplish anything.
Even here, however, there are tradeoffs. You can attach yourself to the story of a company, dedicating yourself to that single brand. To expand this a little, then, you should focus on stories about solving problems for people rather than stories about a product or technology. This might mean telling people they are wrong, by the way—sometimes the best thing is not what someone thinks they want.
Stories are ultimately about people. This is something not many people in engineering fields like to hear, because most of us are in these kinds of fields because we are either introverted, or because we struggle to relate to people in some other way.
To expand this a bit more, you should be willing to tell multiple stories, rather than just one. These stories might overlap or intersect, of course—I have been invested in a story about reducing complexity, disaggregation, and understanding why rather than how for the last ten or fifteen years. These three stories are, in many ways, the same story, just told from different perspectives. You need to allow the story to be shaped, and the path to tell that story to change, over time.
Realize your work is neither as bad as you think it is, nor as good as you think it is. Do not take criticism personally. This is a lesson I had to learn the hard way, from receiving many manuscripts back covered in red marks, either physical or virtual. Failure is not an option; it is a requirement. The more you fail, the more you will actively seek out the tradeoffs, and approach problems and people with humility.
Finally, you need to internalize modularity. Do not try to solve all the problems with a single solution, no matter how neat or new. Part of this is going to go back to understanding why things work the way they do and the limits of people (including yourself!). Solve problems incrementally and set limits on what you will try to do with any single technology.
Ultimately, refusing to become overly attached is a matter of attitude. It is something that is learned through hard work, a skill developed across time.
When should you use IPv6 PA space?
I was reading RFC8475 this week, which describes some IPv6 multihoming ‘net connection solutions. This set me to thinking about when you should uses IPv6 PA space. To begin, it’s useful to review the concept of IPv6 PI and PA space.
PI, or provider independent, space, is assigned by a regional routing registry to network operators who can show they need an address space that is not tied to a service provider. These requirements generally involve having a specific number of hosts, showing growth in the number of IPv6 addresses used over time, and other factors which depend on the regional registry providing the address space. PA, or provider assigned, IPv6 addresses can be assigned by a provider from their PI pool to an operator to which they are providing connectivity service.
There are two main differences between these two kinds of addresses. PI space is portable, which means the operator can take the address space when them when they change providers. PI space is also fixed; it is (generally) safe to use PI space as you might private or other IP address spaces; you can assign them to individual subnets, hosts, etc., and count on them remaining the same over time. If everyone obtained PI space, however, the IPv6 routing table in the default free zone (DFZ) could explode. PI space cannot be aggregated by the operator’s upstream provider because it is portable in just this way.
PA space, on the other hand, can be aggregated by your upstream provider because it is assigned by the provider. On the other hand, the provider can change the address block assigned to its customer at any time. The general idea is the renumbering capabilities built into IPv6 make it possible to “not care” about the addresses assigned to individual hosts on your network.
How does this work out in real life? Consider the following network—

Assume AS65000 assigns 2001:db8:1:1::/64 to the operator, and AS65001 assigns 2001:db8:2:2::/64. IPv6 provides mechanisms for A, B, and D to obtain addresses from within these two ranges, so each device has two IP addresses. Now assume A wants to send a packet to some site connected to the public Internet. If it sources the packet from its address in the 1:1::/64 range, A should send the packet to E; if it sources the packet from its address in the 2:2::/64 range, it should send the packet to F. This behavior is described in RFC6724, rule 5.5:
Prefer addresses in a prefix advertised by the next-hop. If SA or SA’s prefix is assigned by the selected next-hop that will be used to send to D and SB or SB’s prefix is assigned by a different next-hop, then prefer SA. Similarly, if SB or SB’s prefix is assigned by the next-hop that will be used to send to D and SA or SA’s prefix is assigned by a different next-hop, then prefer SB.
If the host uses this solution, it needs to remember which sources it has used in the past for which destinations—at least for the length of a single session, at any rate. RFC6724, however, notes supporting rule 5.5 is a SHOULD, rather than a MUST, which means some hosts may not have this capability. What should the network operator do in this case?
RFC8475 suggests using a set of policy based routing or filter based forwarding policies at the routers in the network to compensate. If E, for instance, receives a packet with a source in the range 2:2::/64 range, it should route the packet to F for forwarding. This will generally mean forwarding the packet out the interface on which E received the packet. Likewise, F should have a local policy that forwards packets it receives with a source address in the 1:1::/64 range to E. RFC8475 provides several examples of policies which would work for a number of different situations (for active/standby, active/active, one border router or two).
There are, however, two failure modes here. For the first one, assume AS65000 decides to assign the operator another IPv6 address range. IPv6’s renumbering capabilities will take care of getting the correct addresses onto A, B, and D—but the policies at E and F must be manually updated for the new address space to work correctly. It should be possible to automate the management of these filters in some way, of course, but the complexity injected into the network is larger than you might initially think.
The second failure relates to a deeper problem. What if B is not allowed, by policy, to talk to D? If the addressing in the network were consistent, the operator could set up a filter at C to prevent traffic from flowing between these two devices. When the network is renumbered, any such filters must be reconfigured, of course. A second instance of this same kind of failure: what if D is the internal DNS server for the network? While the DNS server’s address can be pushed out through the IPv6 renumbering capabilities (through NA, specifically), some manual or automated configuration must be adjusted to get the new address into the IPv6 advertisements so it can be distributed.
The short answer to the question above—when should you use PA space for a network?—comes down to this: when you have a very small, simple network behind a set of routers connecting to the ‘net, where the hosts attached to the network support RFC6724 rule 5.5, and intra-site communication is very simple (or there is no intra-site communications at all). Essentially, renumbering is not the only problem to solve when renumbering a network.
The BGP Monitoring Protocol (BMP)
If you run connections to the ‘net at any scale, even if you are an “enterprise” (still a jinxed term, IMHO), you will quickly find it would be very useful to have a time series record of the changes in BGP at your edge. Even if you are an “enterprise,” knowing what changes have taken place in the routes your providers have advertised to you can make a big difference in tracking down an application performance issue, or knowing just when a particular service went off line. Getting this kind of information, however, can be difficult.
BGP is often overloaded for use in data center fabrics, as well (though I look forward to the day when the link state alternatives to this are available, so we can stop using BGP this way). Getting a time series view of BGP updates in a fabric is often crucial to understanding how the fabric converges, and how routing convergence events correlate to application issues.
One solution is to set up the BGP Monitoring Protocol (BMP—an abbreviation within an abbreviation, in the finest engineering tradition).
BMP is described in RFC7854 as a protocol intended to “provide a convenient interface for obtaining route views.” How is BMP different from setting up an open source BGP process and peering with all of your edge speakers? If you peer using eBGP, you will not see parroted updates unless you look for them; if you peer using iBGP, you might not receive all the updates (depending on how things are configured). However you peer, you will not get a “time series” view of the updates along your edge that can be correlated with other events in your network. Any time you peer using BGP, you are receiving routes after bestpath.
When you pull a BMP feed, in contrast, you are getting the BGP updates as the speaker sees them—before bestpath, before inbound filters, etc. This means you receive a full feed just as the edge speaker receives it. This is all provided in a format that is easily pushed into a database and correlated through timestamps—a huge wealth of information that can be quite useful not only to monitor the health of your network edge, but for troubleshooting. BMP includes messaging for:
- An initial dump of the current BGP table, called route monitoring
- Peer down notification, including a code indicating why the peer went down
- Stat reports, including number of prefixes rejected by inbound policy, number of duplicate prefixes, number of duplicate withdraws, etc.
- Peer up notification
- Route mirroring, in which the speaker sends copies of updates it is receiving
To set BMP up, you need to start with a BGP speaker that supports sending a BMP feed. Juniper supports BMP, as does Cisco. The second thing you will need is a BMP collector, a handy open source version of which is available at openbmp.org.
You will note that the openbmp collector has interfaces to a RESTful database interface, as well as a KAFKA producer. One of these two interfaces should allow you to tie BMP into your existing network management system, or set up a new database to collect the information.
BMP is becoming a bit of an ecosystem in its own right; the GROW working group has already a draft to extend BMP to report on the local routing table, which would allow you to see what is received by BGP but not installed. Another draft accepted by the GROW WG extends BMP to support the adj-rib-out, which would allow you to see the difference between what a BGP speaker receives and what it sends to its peers.
Several other drafts have been proposed but not accepted by GROW, including adding a namespace for the BGP peer up event, and using BMP as part of a BGP based traffic engineering system.
Hopefully, at some point in the future, I’ll be able to follow this post up with a small lab showing what BMP looks like in operation. For now, though, you should definitely try setting BMP up in your network if you have any sort of ‘net edge scale, or a data center using BGP as its IGP.
Research: Legal Barriers to RPKI Deployment
Much like most other problems in technology, securing the reachability (routing) information in the internet core as much or more of a people problem than it is a technology problem. While BGP security can never be perfect (in an imperfect world, the quest for perfection is often the cause of a good solution’s failure), there are several solutions which could be used to provide the information network operators need to determine if they can trust a particular piece of routing information or not. For instance, graph overlays for path validation, or the RPKI system for origin validation. Solving the technical problem, however, only carries us a small way towards “solving the problem.”
One of the many ramifications of deploying a new system—one we do not often think about from a purely technology perspective—is the legal ramifications. Assume, for a moment, that some authority were to publicly validate that some address, such as 2001:db8:3e8:1210::/64, belongs to a particular entity, say bigbank, and that the AS number of this same entity is 65000. On receiving an update from a BGP peer, if you note the route to x:1210::/64 ends in AS 65000, you might think you are safe in using this path to reach destinations located in bigbank’s network.
What if the route has been hijacked? What if the validator is wrong, and has misidentified—or been fooled into misidentifying—the connection between AS65000 and the x:1210::/64 route? What if, based on this information, critical financial information is transmitted to an end point which ultimately turns out to be an attacker, and this attacker uses this falsified routing information to steal millions (or billions) of dollars?
Who is responsible? This legal question ultimately plays into the way numbering authorities allow the certificates they issue to be used. Numbering authorities—specifically ARIN, which is responsible for numbering throughout North America—do not want the RPKI data misused in a way that can leave them legally responsible for the results. Some background is helpful.
The RPKI data, in each region, is stored in a database; each RPKI object (essentially and loosely) contains an origin AS/IP address pair. These are signed using a private key and can be validated using the matching public key. Somehow the public key itself must be validated; ultimately, there is a chain, or hierarchy, of trust, leading to some sort of root. The trust anchor is described in a file called the Trust Anchor Locator, or TAL. ARIN wraps access to their TAL in a strong indemnification clause to protect themselves from the sort of situation described above (and others). Many companies, particularly in the United States, will not accept the legal contract involved without a thorough investigation of their own culpability in any given situation involving misrouting traffic, which ultimately means many companies will simply not use the data, and RPKI is not deployed.
The essential point the paper makes is: is this clause really necessary? Thy authors make several arguments towards removing the strict legal requirements around the use of the data in the TAL provided by ARIN. First, they argue the bounds of potential liability are uncertain, and will shift as the RPKI is more widely deployed. Second, they argue the situations where harm can come from use of the RPKI data needs to be more carefully framed and understood, and how these kinds of legal issues have been used in the past. To this end, the authors argue strict liability is not likely to be raised, and negligence liability can probably be mitigated. They offer an alternative mechanism using straight contract law to limit the liability to ARIN in situations where the RPKI data is misused or incorrect.
Whether this paper causes ARIN to rethink its legal position or not is yet to be seen. At the same time, while these kinds of discussions often leave network engineers flat-out bored, the implications for the Internet are important. This is an excellent example of an intersection between technology and policy, a realm network operators and engineers need to pay more attention to.
Whither Network Engineering? (Part 3)
In the previous two parts of this series, I have looked at the reasons I think the networking ecosystem is bound to change and why I think disaggregation is going to play a major role in that change. If I am right about the changes happening, what will become of network engineers? The bifurcation of knowledge, combined with the kinds of networks and companies noted in the previous posts in this series, point the way. There will, I think, be three distinct careers where the current “network engineer” currently exists on the operational side:
- Moving up the stack, towards business, the more management role. This will be captured primarily by the companies that operate in market verticals deep and narrow enough to survive without a strong focus on data, and hence can survive a transition to black box, fully integrated solutions. This position will largely be focused on deploying, integrating, and automating vertically integrated, vendor-driven systems and managing vendor relationships.
- Moving up the stack, towards software and business, the disaggregated network engineering role (I don’t have a better name for this presently). This will be in support of companies that value data to the point of focusing on its management as a separate “thing.” The network will no longer be a “separate line item,” however, but rather part of a larger system revolving around the data that makes the company “go.”
- Moving down the stack, towards the hardware, the network hardware, rack-and-stack, cabling, power, etc., engineer. Again, I do not have a good name for this role right now.
There will still be a fairly strong “soft division” between design and troubleshooting in the second role. Troubleshooting will primarily be handled by the vendor in the first role.
Perhaps the diagram below will help illustrate what I think is happening, and will continue to happen, in the network engineering field.
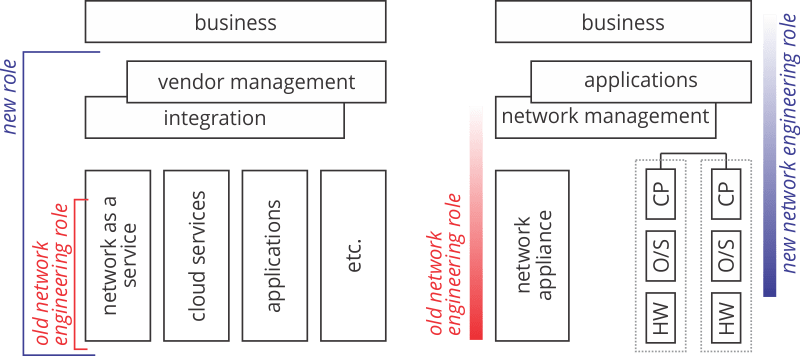
The old network engineering role, shown in the lower left corner of the two halves of the illustration, focused on the appliances and circuits used to build networks, with some portion of the job interacting with protocols and management tools. The goal is to provide the movement of data as a service, with minimal regard to the business value of that data. This role will, in my opinion, transition to the entire left side of the illustration as a company moves to black box solutions. The real value offered in this new role will be in managing the contracts and vendors used to supply what is essentially a commodity.
On the right side is what I think the disaggregated path looks like. Here the network engineering role has largely moved away from hardware; this will increasingly become a largely specialized vendor driven realm of work. On the other end, the network engineer will focused more on software, from protocols to applications, and how they drive and add value to the business. Again, the role will need to move up the stack towards the business to continue adding value; away from hardware, and towards software.
I could well be wrong. I would not be happy or sad if I am right or wrong.
None of these are invalid choices to make, or bad roles to fill. I do not know what role fits “you” best, your life, nor your interests. I am simply observing what I think is happening in the market, and trying to understand where things are going, because I think this kind of thinking helps provide clarity in a confusing world.
In both the first and second roles, you must move up the stack to add value. This is what happened in the worlds of electronic engineering and personal computers as they both disaggregated away from an appliance model. Living through these past experiences is part of what leads me to believe this same kind of movement will happen in the world of networking technology. Further, I think I already see these changes happening in parts of the market, and I cannot see any reason these kinds of changes should not move throughout the entire market fairly rapidly.
What is the percentage of these two roles in the market? Some people think the second role will simply not exist, in fact, other than at vendors. Others think the second role will be a vanishingly small part of the market. I tend to think the percentages will be more balanced because of shifts in the business environment that is happening in parallel with (or rather driving) these changes. Ultimately, however, the number of people in each role will driven by the business environment, rather than the networking world.
Will there be “network engineers” in the future?

If we look at the progress of time from left to right, there is a big bulge ahead, followed by a slope off, and then a long tail. This is my understanding of the current network engineering skill set. We are at A as I write this, just before the big bulge of radical change at B, and I think much farther along than many others believe. At C, there will still be network engineers in the mold of the network engineers of today. They will be valiantly deploying appliance based networks for those companies who have a vertical niche deep enough to survive. There will be vendors still supporting these companies and engineers, too. There will just be a very few of them. Like COBOL and FORTRAN coders today, they will live on the long tail of demand. I suspect a number of the folks who live in this long tail will even consider themselves the “real legacy” of network engineering, while seeing the rest of the network operations and engineering market is more of “software engineers” and “administrators.”
That’s all fine by me; I just know I’d rather be in the bubble of demand than the long tail. 🙂
What should I do as a network engineer? This is the tricky question.
First, I cannot tell you which path to take of the ones I have presented. I cannot, in fact, tell you precisely what these roles are going to look like, nor whether there will be other roles available. For instance, I have not discussed what I think vendors look like after this change at all; there will be some similar roles, and some different ones, in that world.
Second, all the roles I’ve described (other than the hardware focused role) involve moving up the stack into a more software and business focus. This means that to move into these roles, you need to gain some business acumen and some software skills. If this is all correct, then now is the time to gain those skills, rather than later. I intend to post more on these topics in the future, so watch this space.
Third, don’t be fatalistic about any of this. I hear a lot of people say things like “I don’t have any influence over the market or my company.” Wrong. Rather than throwing our hands up in frustration and waiting for our fates (or heads) to be handed to us on a silver platter, I want to suggest a way forward. I know that none of us can entirely control the future—my worldview does not allot the kind of radical freedom this would entail to individual humans. At the same time, I am not a fatalist, and I tend to get frustrated with people who argue they have no control, so we should just “sit back, relax, and enjoy the ride.” We have freedom to do different things in the future within the context and guard rails set by our past decisions (and other things outside the scope of a technical blog).
My suggestion is this: take a hard look at what I have written here, decide for yourself where you think I am right and where I am wrong, and make career decisions based on what you think is going to happen. I have seen multiple people end up at age 50 or 60 with a desire to work, and yet with no job. I cannot tell you what percentage of any particular person’s situation is because of ageism, declining skills, or just being in the wrong place at the wrong time (I tend to think all three play a different role in every person’s situation). On the other hand, if you focus on what you can change—your skills, attitude, and position—and stop worrying so much about the things you cannot change, you will be a happier person.
Fourth, this fatalism stretches to the company you work for, and anyplace you might work in the future. There is a strong belief that network engineers cannot influence business leadership. Let me turn this around: If you stop talking about chipsets and optical transceivers, and start talking about the value of data and how the company needs to think about that value, then you might get a seat at the table when these discussions are taking place. You are not helpless here; if you learn how to talk to the business, there is at least some chance (depending on the company, of course) that you can shape the future of the company you work for. If nothing else, you can use your thinking in this area to help you decide where you want to work next.
Now, let’s talk about some risk factors. While these trends seem strong to me, it is still worth asking: what could take things in a different direction? One thing that would certainly change the outlook would be a major economic crash or failure like the Great Depression. This might seem unthinkable to most people, but more than a few of the thinkers I follow in the economic and political realms are suggesting this kind of thing is possible. If this happens, companies will be holding things together with tin cans, bailing wire, and duct tape; in this case, all bets are off. Another could be the collapse of the entire disaggregation ecosystem. Perhaps another could be someone discovering how to break the State/Optimization/Surface triad, or somehow beat CAP theorem.
There is also the possibility that people, at large, will reject the data driven economy that is developing, intentionally moving back to a more personally focused world with local shopping, and offline friends rather than online. I would personally support such a thing, but but while I think such a move could happen, I do not see it impacting every area of life. The “buy local” mantra is largely focused on bookstores, food, and some other areas. Notice this, however: if “buy local” is really what it means, then it means buying from locally owned stores, rather than shifting from an online retailer to a large chain mixed online/offline retailer. Buy local is not a panacea for appliance based network engineering, and may even help drive the changes I see ahead.
So there you have it: in this first week of 2019, this is what I think is going to happen in the world of networking technology. I could be way wrong, and I am sticking my neck out a good bit in publishing this little series.
As always, this is more of a two-way conversation than you imagine. I read the comments here and on LinkedIn, and even (sometimes) on Twitter, so tell me what you think the network future of network engineering will be. I am not so old, and certain of myself, that I cannot learn new things! 🙂
Whither Network Engineering? (Part 2)
In the first post of this series at the turn of 2019, I considered the forces I think will cause network engineering to radically change. What about the timing of these changes? I hear a lot of people say” “this stuff isn’t coming for twenty years or more, so don’t worry about it… there is plenty of time to adapt.” This optimism seems completely misplaced to me. Markets and ideas are like that old house you pass all the time—you know the one. No-one has maintained it for years, but it is so … solid. It was built out of the best timber, by people who knew what they were doing. The foundation is deep, and it has lasted all these years.
Then one day you pass a heap of wood on the side of the road and realize—this is that old house that seemed so solid just a few days ago. Sometime in the night, that house that was so solid collapsed. The outer shell was covering up a lot of inner rot. Kuhn, in The Structure of Scientific Revolutions, argues this is the way ideas always go. They appear to be solid one day, and then all the supports that looked so solid just moments before the collapse are all shown to be full of termites. The entire system of theories collapses in what seems like a moment compared to the amount of time the theory has stood. History has borne this way of looking at things out.
The point is: we could wake up in five years’ time and find the entire structure of the network engineering market has changed while we were asleep at the console running traceroute. I hear a lot of people talk about how it will take tens of years for any real change to take place because some class of businesses (usually the enterprise) do not take up new things very quickly. This line of thinking assumes the structure of business will remain the same—I think this tends to underestimate the symbiotic relationship between business and information technology. We have become so accustomed to seeing IT as a cost center that has little bearing on the overall business that it is hard to shift our thinking to the new realities that are starting to take hold.
While some niche retailers are doing okay, most of the the broad-based ones are in real trouble. Shopping malls are like ghost towns, bookstores are closing in droves; even grocery stores are struggling in many areas. This is not about second-day delivery—this is about data. Companies must either be in a deep niche or learn to work with data to survive. Companies that can most effectively combine and use data to anticipate, adapt to, and influence consumer behavior will survive. The rest will not.
Let me give some examples that might help. Consider Oak Island Hardware, a local hardware store, Home Depot, Sears, and Amazon. First, there are two kinds of businesses here; while all four have products that overlap, they service two different kinds of needs. In the one case, Home Depot and Oak Island Hardware cater to geographically localized wants where physical presence counts. When your plumbing starts to leak, you don’t have time to wait for next-day delivery. If you are in the middle of rebuilding a wall or a cabinet and you need another box of nails, you are not waiting for a delivery. You will get in your car and drive to the nearest place that sells such things. To some degree, Oak Island Hardware and Home Depot are in a separate kind of market than Sears and Amazon.
Consider Sears and Amazon as a pair first. Amazon internalized its data handling, and builds semi-custom solutions to support that data handling. Sears tried to focus on local stores, inventory management, and other traditional methods of retail. Sears is gone, Amazon remains. So Home Depot and Oak Island Hardware have a “niche” that protects them (to some degree) from the ravages of the data focused world. Now consider Oak Island Hardware versus Home Depot. Here the niche is primarily geographical—there just is not enough room on Oak Island to build a Home Depot. When people need a box of nails “now,” they will often choose the closer store to get those nails.
On the other hand, what kind of IT needs does a stand-alone store like Oak Island Hardware have? I do not think they will be directly hiring any network engineers in the near future. Instead, they will be purchasing IT services in the form of cloud-based applications. These cloud-based applications, in turn, will be hosted on … disaggregated stacks run by providers.
The companies in the broader markets that are doing well have have built fully- or semi-customized systems to handle data efficiently. The network is no longer treated as a “thing” to be built; it is just another part of a larger data delivery system. Ultimately, businesses in broader markets that want to survive need to shift their thinking to data. The most efficient way to do this is to shift to a disaggregated, layered model similar to the one the web- and hyper-scalers have moved to.
I can hear you out there now, reading this, saying: “No! They can’t do this! The average IT shop doesn’t have the skilled people, the vision, the leadership, the… The web- and hyper-scalers have specialized systems built for a single purpose! This stuff doesn’t apply to enterprise networks!”
In answer to this plethora of objections, let me tell you a story.
Once, a long time ago, I was sent off to work on installing a project called PC3; a new US Air Force personnel management system. My job was primarily on the network side of the house, running physical circuits through the on-base systems, installing inverse multiplexers, and making certain the circuits were up and running. At the same time, I had been working on the Xerox STAR system on base, as well as helping design the new network core running a combination of Vines and Netware over optical links connecting Cabletron devices. We already had a bunch of other networks on base, including some ARCnet, token bus, thicknet, thinnet, and a few other things, so packet switching was definitely already a “thing.”
In the process of installing this PC3 system, I must have said something about how this was such old technology, and packet switching was eventually going to take over the world. In return, I got an earful or two from one of the older techs working on the job with me. “Russ,” he said, “you just don’t understand! Packet switching is going to be great for some specialized environments, but circuit switching has already solve the general purpose cases.”
Now, before you laugh at the old codger, he made a bunch of good points. At that time, we were struggling to get a packet switched network up between seven buildings, and then trying to figure out how to feed the packet switched network into more buildings. The circuit switched network, on the other hand, already had more bandwidth into every building on base than we could figure out how to bring to those seven buildings. Yes, we could push a lot more bandwidth across a couple of rooms, but even scaling bandwidth out to an entire large building was a challenge.
What changed? The ecosystem. A lot of smart people bought into the vision of packet switched networking and spent a lot of time figuring out how to make it do all the things no-one thought it could do, and apply it to problems no-one thought it could apply to. They learned how to take the best pieces of circuit-switched technology and apply it in the packet switched world (remember the history of MPLS).
So before you say “disaggregation does not apply to the enterprise,” remember the lesson of packet switched networks—and the lessons of a million other similar technologies. Disaggregation might not apply in the same way to web- and hyper-scale networks and enterprise networks, but this does not mean it does not apply at all. Do not throw the baby out with the bathwater.
As the disaggregation ecosystem grows—and it will grow—the options will become both broader and deeper. Rather than seeing the world as standards versus open-source, we will need learn to see standards plus open source. Instead of seeing the ecosystem as commercial versus open source, we will need to learn to see commercial plus open source. Instead of seeing protocols on appliances supporting applications, we need to will learn to see hardware and software. As the ecosystem grows, we will learn to learn from many places, including appliance-based networking, the world of servers, application development, and … the business. We will need to directly apply what makes sense and learn wisdom from the rest.
What does this mean for network engineering skills? That is the topic of the third post in this series.