Posts by Russ
Whither Network Engineering? (Part 3)
In the previous two parts of this series, I have looked at the reasons I think the networking ecosystem is bound to change and why I think disaggregation is going to play a major role in that change. If I am right about the changes happening, what will become of network engineers? The bifurcation of knowledge, combined with the kinds of networks and companies noted in the previous posts in this series, point the way. There will, I think, be three distinct careers where the current “network engineer” currently exists on the operational side:
- Moving up the stack, towards business, the more management role. This will be captured primarily by the companies that operate in market verticals deep and narrow enough to survive without a strong focus on data, and hence can survive a transition to black box, fully integrated solutions. This position will largely be focused on deploying, integrating, and automating vertically integrated, vendor-driven systems and managing vendor relationships.
- Moving up the stack, towards software and business, the disaggregated network engineering role (I don’t have a better name for this presently). This will be in support of companies that value data to the point of focusing on its management as a separate “thing.” The network will no longer be a “separate line item,” however, but rather part of a larger system revolving around the data that makes the company “go.”
- Moving down the stack, towards the hardware, the network hardware, rack-and-stack, cabling, power, etc., engineer. Again, I do not have a good name for this role right now.
There will still be a fairly strong “soft division” between design and troubleshooting in the second role. Troubleshooting will primarily be handled by the vendor in the first role.
Perhaps the diagram below will help illustrate what I think is happening, and will continue to happen, in the network engineering field.
The old network engineering role, shown in the lower left corner of the two halves of the illustration, focused on the appliances and circuits used to build networks, with some portion of the job interacting with protocols and management tools. The goal is to provide the movement of data as a service, with minimal regard to the business value of that data. This role will, in my opinion, transition to the entire left side of the illustration as a company moves to black box solutions. The real value offered in this new role will be in managing the contracts and vendors used to supply what is essentially a commodity.
On the right side is what I think the disaggregated path looks like. Here the network engineering role has largely moved away from hardware; this will increasingly become a largely specialized vendor driven realm of work. On the other end, the network engineer will focused more on software, from protocols to applications, and how they drive and add value to the business. Again, the role will need to move up the stack towards the business to continue adding value; away from hardware, and towards software.
I could well be wrong. I would not be happy or sad if I am right or wrong.
None of these are invalid choices to make, or bad roles to fill. I do not know what role fits “you” best, your life, nor your interests. I am simply observing what I think is happening in the market, and trying to understand where things are going, because I think this kind of thinking helps provide clarity in a confusing world.
In both the first and second roles, you must move up the stack to add value. This is what happened in the worlds of electronic engineering and personal computers as they both disaggregated away from an appliance model. Living through these past experiences is part of what leads me to believe this same kind of movement will happen in the world of networking technology. Further, I think I already see these changes happening in parts of the market, and I cannot see any reason these kinds of changes should not move throughout the entire market fairly rapidly.
What is the percentage of these two roles in the market? Some people think the second role will simply not exist, in fact, other than at vendors. Others think the second role will be a vanishingly small part of the market. I tend to think the percentages will be more balanced because of shifts in the business environment that is happening in parallel with (or rather driving) these changes. Ultimately, however, the number of people in each role will driven by the business environment, rather than the networking world.
Will there be “network engineers” in the future?

If we look at the progress of time from left to right, there is a big bulge ahead, followed by a slope off, and then a long tail. This is my understanding of the current network engineering skill set. We are at A as I write this, just before the big bulge of radical change at B, and I think much farther along than many others believe. At C, there will still be network engineers in the mold of the network engineers of today. They will be valiantly deploying appliance based networks for those companies who have a vertical niche deep enough to survive. There will be vendors still supporting these companies and engineers, too. There will just be a very few of them. Like COBOL and FORTRAN coders today, they will live on the long tail of demand. I suspect a number of the folks who live in this long tail will even consider themselves the “real legacy” of network engineering, while seeing the rest of the network operations and engineering market is more of “software engineers” and “administrators.”
That’s all fine by me; I just know I’d rather be in the bubble of demand than the long tail. 🙂
What should I do as a network engineer? This is the tricky question.
First, I cannot tell you which path to take of the ones I have presented. I cannot, in fact, tell you precisely what these roles are going to look like, nor whether there will be other roles available. For instance, I have not discussed what I think vendors look like after this change at all; there will be some similar roles, and some different ones, in that world.
Second, all the roles I’ve described (other than the hardware focused role) involve moving up the stack into a more software and business focus. This means that to move into these roles, you need to gain some business acumen and some software skills. If this is all correct, then now is the time to gain those skills, rather than later. I intend to post more on these topics in the future, so watch this space.
Third, don’t be fatalistic about any of this. I hear a lot of people say things like “I don’t have any influence over the market or my company.” Wrong. Rather than throwing our hands up in frustration and waiting for our fates (or heads) to be handed to us on a silver platter, I want to suggest a way forward. I know that none of us can entirely control the future—my worldview does not allot the kind of radical freedom this would entail to individual humans. At the same time, I am not a fatalist, and I tend to get frustrated with people who argue they have no control, so we should just “sit back, relax, and enjoy the ride.” We have freedom to do different things in the future within the context and guard rails set by our past decisions (and other things outside the scope of a technical blog).
My suggestion is this: take a hard look at what I have written here, decide for yourself where you think I am right and where I am wrong, and make career decisions based on what you think is going to happen. I have seen multiple people end up at age 50 or 60 with a desire to work, and yet with no job. I cannot tell you what percentage of any particular person’s situation is because of ageism, declining skills, or just being in the wrong place at the wrong time (I tend to think all three play a different role in every person’s situation). On the other hand, if you focus on what you can change—your skills, attitude, and position—and stop worrying so much about the things you cannot change, you will be a happier person.
Fourth, this fatalism stretches to the company you work for, and anyplace you might work in the future. There is a strong belief that network engineers cannot influence business leadership. Let me turn this around: If you stop talking about chipsets and optical transceivers, and start talking about the value of data and how the company needs to think about that value, then you might get a seat at the table when these discussions are taking place. You are not helpless here; if you learn how to talk to the business, there is at least some chance (depending on the company, of course) that you can shape the future of the company you work for. If nothing else, you can use your thinking in this area to help you decide where you want to work next.
Now, let’s talk about some risk factors. While these trends seem strong to me, it is still worth asking: what could take things in a different direction? One thing that would certainly change the outlook would be a major economic crash or failure like the Great Depression. This might seem unthinkable to most people, but more than a few of the thinkers I follow in the economic and political realms are suggesting this kind of thing is possible. If this happens, companies will be holding things together with tin cans, bailing wire, and duct tape; in this case, all bets are off. Another could be the collapse of the entire disaggregation ecosystem. Perhaps another could be someone discovering how to break the State/Optimization/Surface triad, or somehow beat CAP theorem.
There is also the possibility that people, at large, will reject the data driven economy that is developing, intentionally moving back to a more personally focused world with local shopping, and offline friends rather than online. I would personally support such a thing, but but while I think such a move could happen, I do not see it impacting every area of life. The “buy local” mantra is largely focused on bookstores, food, and some other areas. Notice this, however: if “buy local” is really what it means, then it means buying from locally owned stores, rather than shifting from an online retailer to a large chain mixed online/offline retailer. Buy local is not a panacea for appliance based network engineering, and may even help drive the changes I see ahead.
So there you have it: in this first week of 2019, this is what I think is going to happen in the world of networking technology. I could be way wrong, and I am sticking my neck out a good bit in publishing this little series.
As always, this is more of a two-way conversation than you imagine. I read the comments here and on LinkedIn, and even (sometimes) on Twitter, so tell me what you think the network future of network engineering will be. I am not so old, and certain of myself, that I cannot learn new things! 🙂
Whither Network Engineering? (Part 2)
In the first post of this series at the turn of 2019, I considered the forces I think will cause network engineering to radically change. What about the timing of these changes? I hear a lot of people say” “this stuff isn’t coming for twenty years or more, so don’t worry about it… there is plenty of time to adapt.” This optimism seems completely misplaced to me. Markets and ideas are like that old house you pass all the time—you know the one. No-one has maintained it for years, but it is so … solid. It was built out of the best timber, by people who knew what they were doing. The foundation is deep, and it has lasted all these years.
Then one day you pass a heap of wood on the side of the road and realize—this is that old house that seemed so solid just a few days ago. Sometime in the night, that house that was so solid collapsed. The outer shell was covering up a lot of inner rot. Kuhn, in The Structure of Scientific Revolutions, argues this is the way ideas always go. They appear to be solid one day, and then all the supports that looked so solid just moments before the collapse are all shown to be full of termites. The entire system of theories collapses in what seems like a moment compared to the amount of time the theory has stood. History has borne this way of looking at things out.
The point is: we could wake up in five years’ time and find the entire structure of the network engineering market has changed while we were asleep at the console running traceroute. I hear a lot of people talk about how it will take tens of years for any real change to take place because some class of businesses (usually the enterprise) do not take up new things very quickly. This line of thinking assumes the structure of business will remain the same—I think this tends to underestimate the symbiotic relationship between business and information technology. We have become so accustomed to seeing IT as a cost center that has little bearing on the overall business that it is hard to shift our thinking to the new realities that are starting to take hold.
While some niche retailers are doing okay, most of the the broad-based ones are in real trouble. Shopping malls are like ghost towns, bookstores are closing in droves; even grocery stores are struggling in many areas. This is not about second-day delivery—this is about data. Companies must either be in a deep niche or learn to work with data to survive. Companies that can most effectively combine and use data to anticipate, adapt to, and influence consumer behavior will survive. The rest will not.
Let me give some examples that might help. Consider Oak Island Hardware, a local hardware store, Home Depot, Sears, and Amazon. First, there are two kinds of businesses here; while all four have products that overlap, they service two different kinds of needs. In the one case, Home Depot and Oak Island Hardware cater to geographically localized wants where physical presence counts. When your plumbing starts to leak, you don’t have time to wait for next-day delivery. If you are in the middle of rebuilding a wall or a cabinet and you need another box of nails, you are not waiting for a delivery. You will get in your car and drive to the nearest place that sells such things. To some degree, Oak Island Hardware and Home Depot are in a separate kind of market than Sears and Amazon.
Consider Sears and Amazon as a pair first. Amazon internalized its data handling, and builds semi-custom solutions to support that data handling. Sears tried to focus on local stores, inventory management, and other traditional methods of retail. Sears is gone, Amazon remains. So Home Depot and Oak Island Hardware have a “niche” that protects them (to some degree) from the ravages of the data focused world. Now consider Oak Island Hardware versus Home Depot. Here the niche is primarily geographical—there just is not enough room on Oak Island to build a Home Depot. When people need a box of nails “now,” they will often choose the closer store to get those nails.
On the other hand, what kind of IT needs does a stand-alone store like Oak Island Hardware have? I do not think they will be directly hiring any network engineers in the near future. Instead, they will be purchasing IT services in the form of cloud-based applications. These cloud-based applications, in turn, will be hosted on … disaggregated stacks run by providers.
The companies in the broader markets that are doing well have have built fully- or semi-customized systems to handle data efficiently. The network is no longer treated as a “thing” to be built; it is just another part of a larger data delivery system. Ultimately, businesses in broader markets that want to survive need to shift their thinking to data. The most efficient way to do this is to shift to a disaggregated, layered model similar to the one the web- and hyper-scalers have moved to.
I can hear you out there now, reading this, saying: “No! They can’t do this! The average IT shop doesn’t have the skilled people, the vision, the leadership, the… The web- and hyper-scalers have specialized systems built for a single purpose! This stuff doesn’t apply to enterprise networks!”
In answer to this plethora of objections, let me tell you a story.
Once, a long time ago, I was sent off to work on installing a project called PC3; a new US Air Force personnel management system. My job was primarily on the network side of the house, running physical circuits through the on-base systems, installing inverse multiplexers, and making certain the circuits were up and running. At the same time, I had been working on the Xerox STAR system on base, as well as helping design the new network core running a combination of Vines and Netware over optical links connecting Cabletron devices. We already had a bunch of other networks on base, including some ARCnet, token bus, thicknet, thinnet, and a few other things, so packet switching was definitely already a “thing.”
In the process of installing this PC3 system, I must have said something about how this was such old technology, and packet switching was eventually going to take over the world. In return, I got an earful or two from one of the older techs working on the job with me. “Russ,” he said, “you just don’t understand! Packet switching is going to be great for some specialized environments, but circuit switching has already solve the general purpose cases.”
Now, before you laugh at the old codger, he made a bunch of good points. At that time, we were struggling to get a packet switched network up between seven buildings, and then trying to figure out how to feed the packet switched network into more buildings. The circuit switched network, on the other hand, already had more bandwidth into every building on base than we could figure out how to bring to those seven buildings. Yes, we could push a lot more bandwidth across a couple of rooms, but even scaling bandwidth out to an entire large building was a challenge.
What changed? The ecosystem. A lot of smart people bought into the vision of packet switched networking and spent a lot of time figuring out how to make it do all the things no-one thought it could do, and apply it to problems no-one thought it could apply to. They learned how to take the best pieces of circuit-switched technology and apply it in the packet switched world (remember the history of MPLS).
So before you say “disaggregation does not apply to the enterprise,” remember the lesson of packet switched networks—and the lessons of a million other similar technologies. Disaggregation might not apply in the same way to web- and hyper-scale networks and enterprise networks, but this does not mean it does not apply at all. Do not throw the baby out with the bathwater.
As the disaggregation ecosystem grows—and it will grow—the options will become both broader and deeper. Rather than seeing the world as standards versus open-source, we will need learn to see standards plus open source. Instead of seeing the ecosystem as commercial versus open source, we will need to learn to see commercial plus open source. Instead of seeing protocols on appliances supporting applications, we need to will learn to see hardware and software. As the ecosystem grows, we will learn to learn from many places, including appliance-based networking, the world of servers, application development, and … the business. We will need to directly apply what makes sense and learn wisdom from the rest.
What does this mean for network engineering skills? That is the topic of the third post in this series.
Whither Network Engineering? (Part 1)
An article on successful writers who end up driving delivery trucks. My current reading in epistemology for an upcoming PhD seminar. An article on the bifurcation of network engineering skills. Several conversations on various slacks I participate in. What do these things have in common? Just this:
What is to become of network engineering?
While it seems obvious network engineering is changing, it is not so easy to say how it is changing, and how network engineers can adapt to those changes. To better understand these things, it is good to back up and take in a larger view. A good place to start is to think about how networks are built today.
Networks today are built using an appliance and circuit model. To build a network, an “engineer” (we can argue over the meaning of that word) tries to gauge how much traffic needs to be moved between different points in the business’ geographical space, and then tries to understand the shape of that traffic. Is it layer 2, or layer 3? Which application needs priority over some other application?
Once this set of requirements is drawn up, a long discussion over the right appliances and circuits to purchase to fulfill them. There may be some thought put into the future of the business, and perhaps some slight interaction with the application developers, but, in general, the network is seen pretty much as plumbing. So long as the water glass is filled quickly, and the toilets flush, no-one really cares how it works.
There are many results of building networks this way. First, the appliances tend to be complex devices with many different capabilities. Since a single appliance must serve many different roles for many different customers running many different applications, each appliance must be like a multitool, or those neat kitchen devices you see on television (it slices, it dices, it can even open cans!). While this is neat, it tends to cause technologies to be misapplied, and means each appliance is running tens of millions of lines of code—code very few people understand.
This situation has led, on the one hand, to a desire to simplify. The first way operators are simplifying is to move all their applications to the cloud. Many people see this as replacing just the data center, but this misunderstands the draw of cloud, and why businesses are moving to it. I have heard people say, “oh, there will still be the wide area, and there will still be the campus, even if my company goes entirely to the cloud.” In my opinion, this answer does not effectively grapple with the concept of cloud computing.
If a business desires to divest itself of its network, it will not stop with the data center. 5G, SD-WAN, and edge computing are going to fundamentally change the way campus and WAN are done. If you could place your application in a public cloud service and have the data and application distributed to every remote site without needing a data center, on site equipment, and circuits into each of those remote sites, would you do it? To ask is to know the answer.
If most companies move all their data to cloud service, then the only network engineers who survive will be at those providers, transit providers, and other supporting roles. The catch here is that cloud providers do not treat the network as a separate “thing,” and hence they do not really have “network engineers” in the traditional sense. So in this scenario, the network engineer still changes radically, and there are very few of them around, mostly working for providers of various kinds.
On the other hand, the drive to simplify has led to strongly vertically integrated vendor-based solutions consisting of hardware and software. The easy button, the modern mainframe, or whatever you want to call it. In this case, the network engineer works at the vendor rather than the enterprise. They tend to have very specialized knowledge, and there are few of them.
There is a third option, of course: disaggregation.
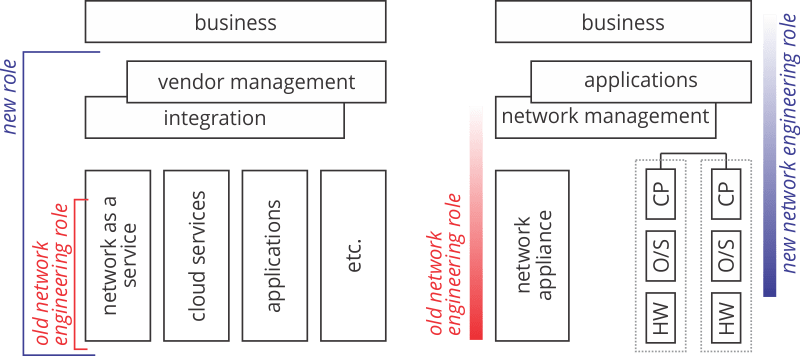
In this third option, the company will invest in the network and applications as a single, combined strategic asset. Like a cloud provider or web scaler, these companies will not see the network as a “thing” to be invested in separately. Here there will be engineers of one kind or another, and a blend of things purchased from vendors and things built in-house. They will see the applications through the hardware as a complete system, rather than as an investment in appliances and circuits. Perhaps the following diagram will help.

The left side of this diagram is how we build networks today: appliances connected through the control plane, with network management and applications riding on top. The disaggregated view of the network treats the control plane somewhat like an application, and the operating system like any other operating system. The hardware is fit to task; this does not mean it is a ”commodity,” but rather that the hardware life cycle and tuning is untied from the optimization of the software operating environment. In the disaggregated view, the software stack is fit to the company and its business, rather than to the hardware. This is the crucial difference between the two models.
There are two ways to view the competition between the company that moves to the cloud, the company that moves to black box integrated solutions, and the company that disaggregates. My view is that the companies that move to the cloud, or choose the block box, will only survive if they live in a fairly narrow niche where the data they collect, produce, and rely on is narrow in scope—or rather, not generally usable.
Those companies that try to live in the broader market, and give their data to a cloud provider, or give their IT systems entirely to a vendor, will be eaten. Why do I think this? Because data is the new oil. Data grants and underlies every kind of power that relates to making any sort of money any longer—political power, social power, supply-chain efficiency, and anything else you can name. There are no chemical companies, there are only data companies. This is the new normal, and companies that do not understand this new normal will either need to be in a niche small enough that their data is unique in a way that protects them, or they will be eaten. George Gilder, in Knowledge and Power, is one of the better explanations of this process you can pick up.
If data is at the heart of your business and you either give it to someone else, or you fail to optimize your use of it, you will be at a business disadvantage. That business disadvantage will grow over time until it becomes an economic millstone around the company itself. Can you say Sears? What about Toys-R-Us?
Technology like 5G, edge computing, and cloud, mixed in with the pressure to reduce the complexity of running a network and subsuming it into the larger life of IT, are forming a wrecking ball directed at network engineering as we know it. Which leaves us with the question: whither network engineering?
Optimal Route Reflection: Next Hop Self
Recently, I posted a video short take I did on BGP optimal route reflection. A reader wrote in the comments to that post:
…why can’t Router set next hop self to updates to router E and avoid this suboptimal path?
To answer this question, it is best to return to the scene of the suboptimality—

To describe the problem again: A and C are sending the same route to B, which is a route reflector. B selects the best path from its perspective, which is through B, and sends this route to each of its clients. In this case, E will learn the path with a next hop of A, even though the path through C is closer from E’s perspective. In the video, I discuss several ways to solve this problem; one option I do not talk about is allowing B to set the next hop to itself. Would this work?
Before answering the question, however, it is important to make one observation: I have drawn this network with B as a router in the forwarding path. In many networks, the route reflector is a virtual machine, or a *nix host, and is not capable of forwarding the traffic required to self the next-hop to itself. There are many advantages to intentionally removing the route reflector from the forwarding path. So while setting nexthop-self might work in this situation, it will not work in all situations.
But will it work in this situation? Not necessarily. The shortest path, for D, is through C, rather than through A. B setting its next hop to itself is going to draw E’s traffic towards 100::/64 towards itself, which is still the longer path from E’s perspective. So while there are situations where setting nexthop-self will resolve this problem, this particular network is not one of them.
Research: BGP Routers and Parrots
The BGP specification suggests implementations should have three tables: the adj-rib-in, the loc-rib, and the adj-rib-out. The first of these three tables should contain the routes (NLRIs and attributes) transmitted by each of the speaker’s peers. The second table should contain the calculated best paths; these are the routes that will be (or are) installed in the local routing table and used to build a forwarding table. The third table contains the routes which have been sent to each peering speaker. Why three tables? Routing protocols standards are (sometimes—not always) written to provide the maximum clarity to how the protocol works to someone who is writing an implementation. Not every table or process described in the specification is implemented, or implemented the way it is described.
What happens when you implement things in a different way than the specification describes? In the case of BGP and the three RIBs, you can get duplicated BGP updates. What do parrots and BGP have in common describes two situations where the lack of a adj-rib-out can cause duplicate BGP updates to be sent.
The authors of this paper begin by observing BGP updates from a full feed off the default free zone. The configuration of the network, however, is designed to provide not only the feed from a BGP speaker, but also the routes received by a BGP speaker, as shown in the illustration below.

In this figure, all the labeled routers are in separate BGP autonomous systems, and the links represent physical connections as well as eBGP sessions. The three BGP updates received by D are stored in three different logs which are time stamped so they can be correlated. The researchers found two instances where duplicate BGP updates were received at D.
In the first case, the best path at C switches between A and B because of the Multiple Exit Discriminator (MED), but the remainder of the update remains the same. C, however, strips the MED before transmitting the route to D, so D simply sees what appears to be duplicate updates. In the second case, the next hop changes because of an implicit withdraw based on a route change for the previous best path. For instance, C might choose A as the best path, but then A implicitly withdraws its path, leaving the path through B as the best. When this occurs, C recalculates the best path and sends it to D; since the next hop is stripped when C advertises the new route to D, this appears to be a duplicate at D.
In both of these cases, if C had an adj-rib-out, it would find the duplicate advertisement and squash it. However, since C has no record of what it has sent to D in the past, it must send information about all local best path changes to D. While this might seem like a trivial amount of processing, these additional updates can add enough load during link flap situations to make a material difference in processor utilization or speed of convergence.
Why do implementors decide not to include an adj-rib-out in their implementations, or why, when one is provided, do operators disable the adj-rib-out? Primarily because the adj-rib-out consumes local memory; it is cheaper to push the work to a peer than it is to keep local state that might only rarely be used. This is a classic case of reducing the complexity of the local implementation by pushing additional state (and hence complexity) into the overall system. The authors of the paper suggest a better balance might be achieved if implementations kept a small cache of the most recent updates transmitted to an adjacent speaker; this would allow the implementation to reduce memory usage, while also allowing it to prevent repeating recent updates.
CAA Records and Site Security
The little green lock—now being deprecated by some browsers—provides some level of comfort for many users when entering personal information on a web site. You probably know the little green lock means the traffic between the host and the site is encrypted, but you might not stop to ask the fundamental question of all cryptography: using what key? The quality of an encrypted connection is no better than the quality and source of the keys used to encrypt the data carried across the connection. If the key is compromised, then entire encrypted session is useless.
So where does the key pair come from to encrypt the session between a host and a server? The session key used for symmetric cryptography on each session is obtained using the public key of the server (thus through asymmetric cryptography). How is the public key of the server obtained by the host? Here is where things get interesting.
The older way of doing things was for a list of domains who were trusted to provide a public key for a particular server was carried in HTTP. The host would open a session with a server, which would then provide a list of domains where its public key could be found in the opening HTTP packets. The host would then find one of those hosts, and hence the server’s public key. From there, the host could create the correct nonce and other information to form a session key with the server. If you are quick on the security side, you might note a problem with this solution: if the HTTP session itself is somehow hijacked early in the setup process, a man-in-the-middle could substitute its own host list for the one the server provides. Once this substitution is done, the MITM could set up perfectly valid encrypted sessions with both the host and the server, funneling traffic between them. The MITM now has full access to the unencrypted data flowing through the session, even though the traffic is encrypted as it flows over the rest of the ‘net.
To solve this problem, a new method for finding the server’s public key was designed around 2010. In this method, the host requests the Certificate Authority Authorization (CAA) record from the server’s DNS server. This record lists the domains who are authorized to provide a public key, or certificate, for the servers within a domain. Thus, if you purchase your certificates from BigCertProvider, you would list BigCertProvider’s domain in your CAA. The host can then find the correct DNS record, and retrieve the correct certificate from the DNS system. This cuts out the possibility of a MITM attacking the HTTP session during the initial setup phases. If DNSSEC is deployed, the DNS records should also be secured, preventing MITM attacks from that angle, as well.
The paper under review today examines the deployment of CAA records in the wild, to determine how widely CAAs are deployed and used.
In this paper, a group of researchers put the CAA system to the test to see just how reliable the information is. In their first test, they attempted to request certificates that would cause the issuer to issue invalid certificates in some way; they found that many certificate providers will, in fact, issue such invalid certificates for various reasons. For instance, in one case, they discovered a defect in the provider’s software that allowed their automated system to issue invalid certificates.
In their second test, they examined the results of DNS queries to determine if DNS operators were supporting and returning CAA certificates. They discovered that very few certificate authorities deploy security controls on CAA lookups, leaving open the possibility of the lookups themselves being hijacked. Finally, they examine the deployment of CAA in the wild by web site operators. They found CAA is not widely deployed, with CAA records covering around 40,000 domains. DNSSEC and CAA deployment generally overlap, pointing to a small section of the global ‘net that is concerned about the security of their web sites.
Overall, the results of this study were not heartening for the overall security of the ‘net. While the HTTP based mechanism of discovering a server’s certificate is being deprecated, not many domains have started deploying the CAA infrastructure to replace it—in fact, only a small number of DNS providers support users entering their CAA certificate into their domain records.
Research: Measuring IP Liveness
Of the 4.2 billion IPv4 addresses available in the global space, how many are used—or rather, how many are “alive?” Given the increasing usage of IPv6, it might seem this is an unimportant question. Answering the question, however, resolves to another question that is actually more important: how can you determine whether or not an IP address is in use? This question might seem easy to answer: ping every address in the address space. This, however, turns out to be the wrong answer.
Scanning the Internet for Liveness. SIGCOMM Comput. Commun. Rev. 48, 2 (May 2018), 2-9. DOI: https://doi.org/10.1145/3213232.3213234
This answer is wrong because a substantial number of systems do not respond to ICMP requests. According to this paper, in fact, some 16% of the hosts they discovered that would respond to a TCP SYN, and another 2% that would respond to a UDP packet shaped to connect to a service, do not respond to ICMP requests. There are a number of possible reasons for this situation, including hosts being placed behind devices that block ICMP packets, hosts being configured not to respond to ICMP requests, or a server sitting behind a PAT or CGNAT device that only passes through service requests rather than all packets.
The paper begins by building a taxonomy of liveness, describing the process they use to determine if an address is in use or not, as shown in the image replicated from the paper.

One problem of note is that address usage can shift over time; between trying to use ICMP and a TCP SYN to determine if an IP address is in use, the device connected to that address can change. To limit the impact of this problem, the researchers sent each kind of liveness test to the same address close together in time. The authors then attempt to cross reference the liveness indicated using different techniques to an overall view of liveness for a particular address.
The research resulted in a number of interesting observations, such as the 16% of hosts that respond to TCP SYN probes on some port, but do not respond to ICMP requests. The kinds of ICMP and TCP responses was also quite interesting; many TCP implementations do not seem compliant to the TCP specification in how they respond to a SYN request.
Along the way, the authors added new capabilities to ZMap which allow them to perform these measurements. The tool they used has a web based frontend, and can be accessed here.
The results are interesting for network operators because they indicate the kinds of work required to find all the devices attached to a network using IP addresses—a mass ping utility is simply not enough. The tools developed here, and the lessons learned, can be added to the set of tools used by operators in all networks to better understand their IP address usage, and the shape of their networks.